This is an application of Apache Hadoop MapReduce framework. Facebook has a feature that says that, some people may be your friends. This is calculated based on a number of factors such as common friends, likes, visits to profile,
comments made etc. Basically the interactions is logged, analyzed and put through a kind of weighted matrix analysis and the connections which are above a threshold value are chosen to be shown to the user.
Problem: An input file of 1GB size with the logs of interactions among 26,849 people. To keep the data manageable on my computer, I am creating random logs with interaction of 1000 people with the rest of the people on the, say social
networking site. Gathering and presenting this data to map reduce is itself a job. In our case, these 1000 people need friend suggestions.
Solution: Here this is done in a Single map reduce job although, more data and intermediate jobs can be added in real life. The mapper for the job takes each interaction and emits the user pair and interaction statistics. For example,
Sam Worthington has 1 profile view, 2 friends in common, 3 likes with Stuart Little. so the out put of the mapper here is. We could use the userid across the site rather than a name. For each person interacting with Stuart Little a record like this is produced.
The reducer simply takes the output of the mapper and calculates the sum of the interactions per user-user pair. So, for a week of interactions the record from the reducer may be, for example,. This is got by summing up the interactions by the reducer. Then, each interaction can be given a weight/value then, the number in the record can be multiplied by the weight and summed. Any calculation is ok as long as it give a meaning result based on the interaction types. Then, interactions with a score larger than a threshold can be chosen to be presented to the user when they login.
Other factors like user interests, activities etc can also be accounted for. Here we can simple treat each as a user and emit a record if there is a related activity in user's profile and proceed as usual. The same approach can be applied to ad serving utilizing info from user profile and activity. A Combiner and mutiple jobs can be used to get more details too.
Results: For 1GB, in real life big data approaches > 2TB, of randomly generated log of interactions of 26K+ people with a select 1000, the mapreduce program gave the friend suggestions in 13 mintues on my laptop with a pseudo distributed Hadoop configuration. So, if you have a few tera bytes of data and 10 computers in a cluster you can get the result in say 1.5 hours. Then all that is needed would be to consume the friend suggestions via a regular db / webservice and present it to the user when they log in.
Screen shots of the Map Reduce job run on pseudo distributed Hadoop:
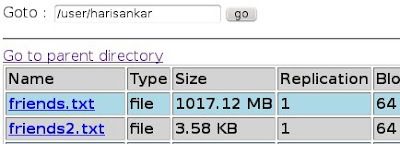
1) Copying the data to Hadoop Distributed File System

2) Running the jobs

3) Status on Hadoop admin interface.


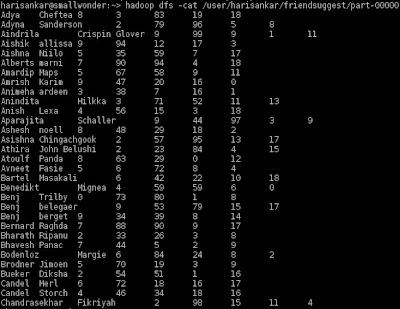
4) Friend Suggestions with statistics.
5) Job code

6) Mapper

7) Reducer

comments made etc. Basically the interactions is logged, analyzed and put through a kind of weighted matrix analysis and the connections which are above a threshold value are chosen to be shown to the user.
Problem: An input file of 1GB size with the logs of interactions among 26,849 people. To keep the data manageable on my computer, I am creating random logs with interaction of 1000 people with the rest of the people on the, say social
networking site. Gathering and presenting this data to map reduce is itself a job. In our case, these 1000 people need friend suggestions.
Solution: Here this is done in a Single map reduce job although, more data and intermediate jobs can be added in real life. The mapper for the job takes each interaction and emits the user pair and interaction statistics. For example,
Sam Worthington has 1 profile view, 2 friends in common, 3 likes with Stuart Little. so the out put of the mapper here is
The reducer simply takes the output of the mapper and calculates the sum of the interactions per user-user pair. So, for a week of interactions the record from the reducer may be, for example,
Other factors like user interests, activities etc can also be accounted for. Here we can simple treat each as a user and emit a record if there is a related activity in user's profile and proceed as usual. The same approach can be applied to ad serving utilizing info from user profile and activity. A Combiner and mutiple jobs can be used to get more details too.
Results: For 1GB, in real life big data approaches > 2TB, of randomly generated log of interactions of 26K+ people with a select 1000, the mapreduce program gave the friend suggestions in 13 mintues on my laptop with a pseudo distributed Hadoop configuration. So, if you have a few tera bytes of data and 10 computers in a cluster you can get the result in say 1.5 hours. Then all that is needed would be to consume the friend suggestions via a regular db / webservice and present it to the user when they log in.
Screen shots of the Map Reduce job run on pseudo distributed Hadoop:
1) Copying the data to Hadoop Distributed File System

2) Running the jobs

3) Status on Hadoop admin interface.


4) Friend Suggestions with statistics.

5) Job code

6) Mapper

7) Reducer

No comments:
Post a Comment