In one of the earlier posts I had called for the use of binary search trees for set representation and general search operations. I take it back. Now it is splay trees !. These are very similar to binary search trees but, these ones are balanced binary search trees. A binary search tree gives you log(n) of search and insertion theoretically. This is true only of the keys that are going into the tree are totally random. So if the set of keys { 10, 2, 38, 63, 21, 9, 1} go into a binary search tree then, the tree looks like

This tree gives you log(n) time on its search. It is balanced too. But, if the application was putting in data in not-so random way then the tree can easily become unbalanced. This can lead to n time search. so if keys were to go in like { 1, 2, 9, 10, 21, 38, 63 }. Then the tree looks like

This seems ok with the defenition of the search tree but, if you were searching for 63 then, you need to do 7 comparisons compared to 3 in the previous tree. Also, recently accessed data may be frequently needed. Effectively this will turn into a list. In a splay tree, all operations are similar to a binary search tree but, you bubble up the recently accessed node up to the root or the first level from root. So next time you access it, the node will be available real fast. The bubble up will cost some time but, will compensate over a number of operations with the efficiency of balancing the tree. For splay tree the average of a collection of operations is always of the order of log(n) although some of these operations may be of n time complexity. Accessing a node means searching / inserting / deleting. In all these cases we bubble up the node / the node that replaced it in the case of deletion.
The process of bubbling up the node consists of left rotations and right rotations. The algorithms to bubble up the node / balance the tree has three conditions.
1) If the node is a right child of a left child then you rotate the node left once and then rotate it right. (vice versa also for this case)
2) If the node is the right child of a right child then, you rotate the parent left once and then the node also once to left. (vice versa also for this case)
3) This has to be done until the node reaches the root or the first level from root.
So for a set of keys { 18, 12, 25, 4, 15, 26, 1, 13, 17, 30, 3, 14, 28, 29} suppose the tree looks like this before any splay. We access 3 in 4 operations.
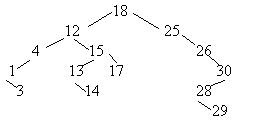
For splaying, 3 is the right child of a left child so we rotate it left once and then right again. The left rotation gives a tree like this

Then a right rotation again gives

Again since 3 is the left child of a left child we do right rotations. one at 12 then at 3. This brings 3 to the root.

Next time we do a search for 3 we get a faster response. Also, the tree is better balanced so, we get a better time for any node than before.
A run time profiling example: Tree is created with values from 0 - 99999 in order. Then 99999 is searched before and after splaying. The cpu runtime profiling results are shown below.

Another profiling result, to get a feel of the advantage, (constructing the same tree as before) 4 values near leaf and 1 value near mid section are searched together. Both before and after splaying. The run time results are shown below.
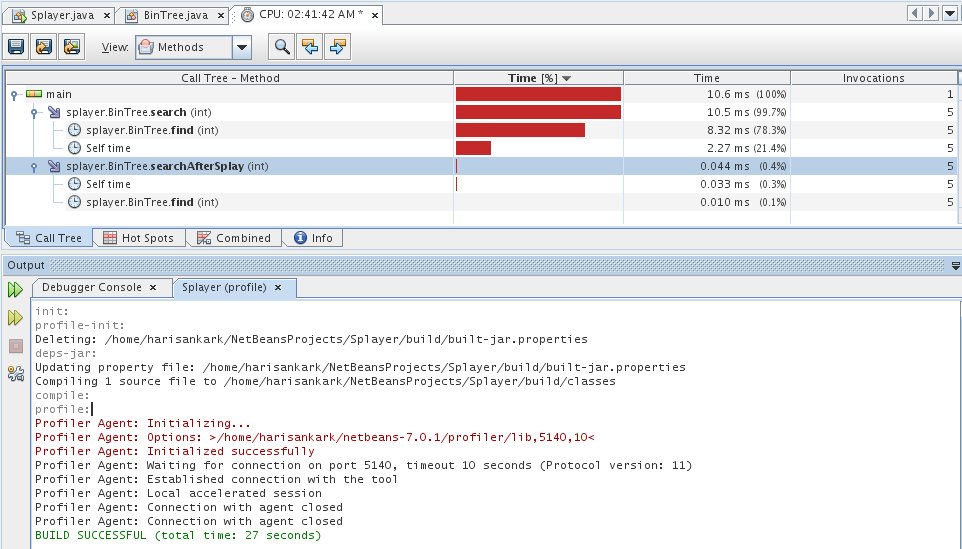
Obviously, splay operation has an advantage on an average since, the tree is now balanced and we can find any value in less than half time than before.
No comments:
Post a Comment